 Home
Home
 Oct 28, 2021
Oct 28, 2021

Are Flower Shops Still Relevant? | Turkish Sentiment Analyzer
This article demonstrates the ease of text mining using Repustate’s sentiment analysis platform and highlights the technology behind it. For this instance, I decided to choose Repustate’s Turkish sentiment analyzer capability and do an analysis of a well-known online flower shop in Turkey.
Saying It With Flowers
It took a pandemic for us to realize the things we take for granted. A simple coffee in a coffee shop, a movie with pals, a haircut, a dentist appointment - all of this became extraordinary in the strange times that Covid19 brought. Given all this, there was a New York Times article I saw sometime back, which said that people had started using flower services more than ever during Covid19, even as the industry was struggling because of the restrictions on movement, shortage of resources, and canceled events. This was in contrast to an article I’d read back in 2017, about how an ad campaign run by Ogilvy & Mather showed that the flower industry was struggling, albeit because of their own complacency and unwillingness to move ahead with the times.
I was intrigued with this development and thought why not do sentiment analysis on flower shops through social media listening and see what consumers are actually feeling and thinking about the whole thing. To put a twist, because Repustate IQ analyzes 23 languages natively, I decided to do it in Turkish. After all, Turkey’s a lovely country, diverse and heterogeneous, and with a people known for their hospitality and generosity.
How Is Sentiment Mining Of Turkish Text Done Using Repustate IQ?
Here’s what I did. I chose a very popular online flower shop in Turkey and gathered 10,000 of their reviews. I then uploaded the reviews onto Repustate IQ to begin analyzing sentiment in Turkish text.
Using Turkish natural language processing to analyze sentiment in Turkish text, Repustate IQ analyzed all the data for sentiment and semantic analysis in real-time and uploaded the information on its dashboard. You can immediately see that the overall sentiment of the flower shop (shown in green) is very positive.
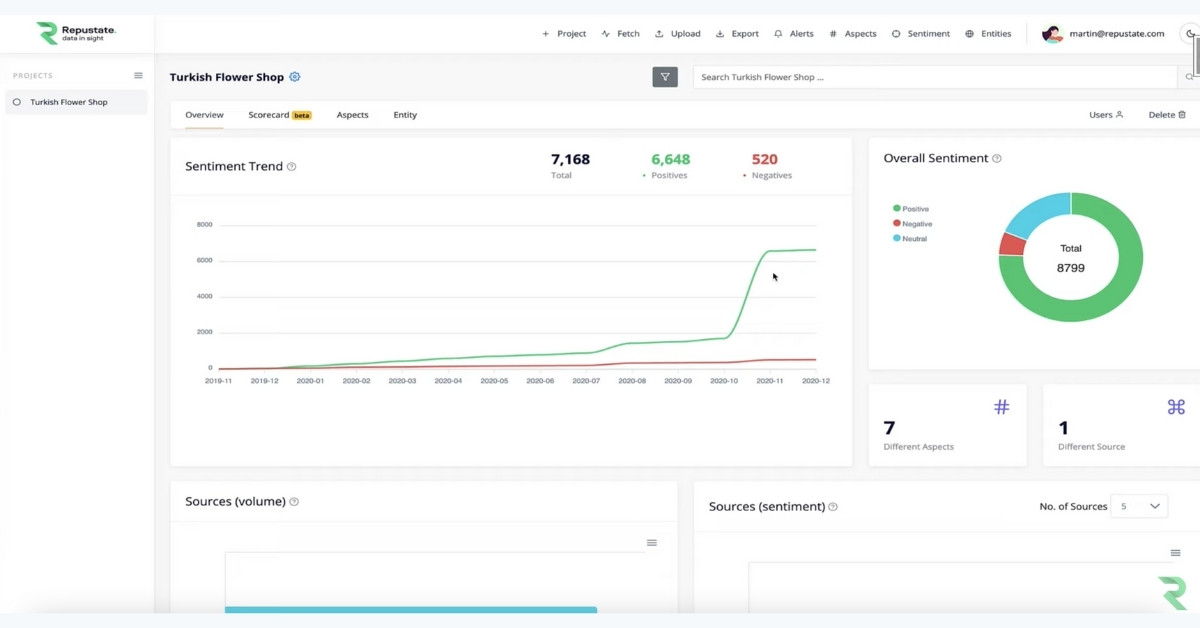
A deep dive into aspect-based sentiment shows us which aspects of the service people liked the most and which were most likely the driving force behind the company’s success. Delivery, appearance, and even an emotion like gratitude, were found to be the most commonly mentioned aspects in these reviews.
Repustate IQ’s sentiment analysis dashboard also shows you the emotions people are expressing and what aspects occur with which emotion. All of this analysis is done natively in Turkish, without translations. The video also shows the named identities mentioned, all of which are in Turkish.
Watch the Turkish sentiment analyzer video
Overall, the one thing that came through from this voice of the customer exercise was that not only did people love sending flowers to each other during a time when we can instantly connect through our digital devices, but especially because of a period that saw restrictions on gatherings and family events. People suddenly realized how unpredictable life could be, and in the bargain helped resurrect the struggling flower industry. It’s the same story in North America.
Major Problems In Turkish Text Sentiment Mining
Back to text mining in Turkish. Well, Turkish is very different from English. Turkish lexicon does not have grammatical gender and no order in the sentence structure regarding the subject, object, or verb. Another very interesting aspect of the Turkish language is that it’s heavily influenced by vast and varied languages including Romance languages (languages derived from Latin between the 3rd and 8th centuries such as French and Italian), as well as German, Persian, Arabic, and most recently, English. This makes it difficult for AI and natural language processing models to analyze sentiment in Turkish text because it’s a living language that is constantly evolving. A Turkish sentiment analyzer platform needs to be constantly up to date to be relevant and give accurate results, or else it will become redundant.
Added to this, Turkish has numerous productive derivational morphemes, which means that it has an infinite word lexicon because of which fixed size tag/feature encoding schemes do not work in NLP tasks. There are many more challenges that data scientists face including derivative and syntactic relations in Turkish word structure and the different inflectional groups of a word that can be involved in different syntactic relations. But all of that for a technical blog, perhaps later.
How Do We Do Turkish Sentiment Analysis Without Any Translations?
This is a 6-step process in which machine learning and Turkish natural language processing tasks are combined to derive sentiment from Turkish text.
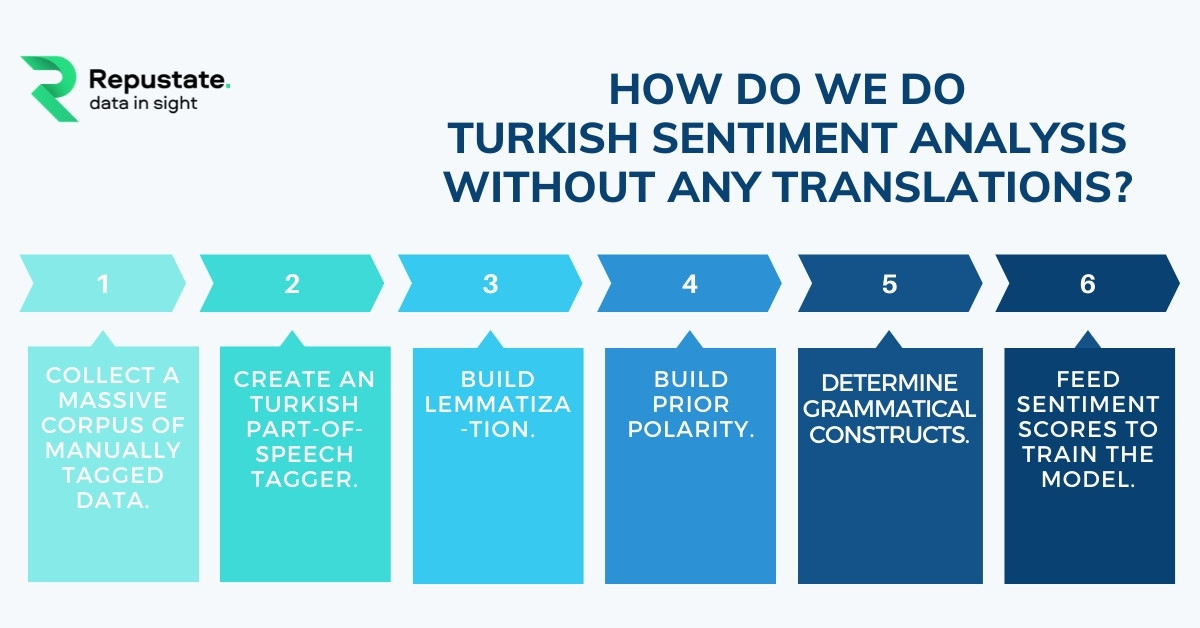
- Step 1: Collect a massive corpus of manually tagged data
Collect a massive corpus of manually tagged dataFirst we collect a massive and diverse Turkish corpus and clean it up.
- Step 2: Create a Turkish part-of-speech tagger
Create a Turkish part-of-speech taggerNow we create a part-of-speech tagger for the language. Each Turkish word is classified so it can be identified for conjunctions, subordinate clauses, prepositional, and noun phrases. This is what separates Repustate IQ from other platforms in the market that claim to be multilingual but in reality, use English translations instead of native language speech taggers under the hood to analyze a non-English language.
- Step 3: Build lemmatization
Build lemmatizationWe apply the rules of conjugating nouns and verbs based on gender, tense, etc. in the model through lemmatization. This helps the model determine the root of a word while mining in Turkish text.
- Step 4: Build prior polarity
Build prior polarityIn this step, we determine the positive and negative context of the word, where Excellent could be +1, good +0.5, and poor as -0.5. Ultimately, this is what helps give each review a sentiment score. Eventually, the sentiment analysis API will give the aggregate score of the brand we are analyzing in the range of 0 to 100, 100 being the highest positive score.
- Step 5: Determine grammatical constructs
Determine grammatical constructsGrammatical constructs are determined so that the Turkish sentiment analyzer can read the Turkish text natively. Different languages have different rules when it comes to negations and amplifiers, so this step is key.
- Step 6: Feed sentiment scores to train the model
Feed sentiment scores to train the modelSentiment scores are now aggregated for the entire Turkish content that you want to analyze. We can get as granular as needed. Aspect-based sentiment analysis is the most detailed. All these findings are thus shown in a sentiment analysis dashboard.
Even if the content we analyze is a video source, the platform’s video content analysis capability applies the same steps by first transcribing the Turkish audio to text.
Turkish Text Datasets
The accuracy of the text mining platform depends on the collection of vast and diverse data or dataset that we use to feed into a machine-learning algorithm to train it. The more diverse and labeled the dataset is, the more efficient the model will be. Apart from this, we need another dataset called the validation dataset, to test the model once it is trained. This helps us know how accurate the algorithm is. The model is retrained accordingly and eventually, it reaches its optimum accuracy. Here are a couple of Turkish dataset repositories from where you can get free Turkish datasets to use in machine learning.
-
Datasets - Turkey (knoema.com) - You can find datasets on possibly every topic you can think of for text mining in Turkish on this website. Right from the number of women in managerial positions to oil pipeline transportation and operations.
-
Turkish data.world - There are 79 Turkish datasets available on this website ranging from gender analysis reports to wildlife inventory plans.
-
Turkish Datasets - NLP Database - Here you can find free Turkish datasets for training your NLP model.
-
Machine Learning Datasets - There are 36 comprehensive Turkish datasets you can use from this portal. It includes audio datasets, cross-lingual question answering datasets (XQuAD), multilingual parallel corpora, and others.
-
A Turkish Dataset for Twitter Users - This dataset contains information about the gender of Twitter users for author profiling that you can use to analyze sentiment in Turkish text.
Repustate IQ For Consumer Insights
Ultimately, every challenge a brand or industry faces, is an opportunity for it to take stock of the situation and do a growth-gap analysis. Complacency can bring even the most robust industry to a standstill during an unpredictable situation, just as the example of the flower industry has shown us. Continually bettering oneself by using advanced tools to monitor growth and foster greater efficiency and productivity can help brands reap mighty rewards in the long run.
Brands need to develop a wise customer experience strategy built on sound consumer insights delivered by an intelligent AI-powered sentiment analysis platform. These insights can give you indepth information on consumer behaviour, emerging market trends, and competitor brands, so you can strategize effective marketing campaigns and take advantage of new opportunities.
Whether you are analyzing sentiment in Turkish text or any other of the 23 languages that Repustate IQ supports, you will find the most accurate customer or employee insights you are looking for. The platform is available as an on-prem installation as well as a Cloud API.
 Jeremy Wemple
Jeremy Wemple
 Dr. Ayman Abdelazem
Dr. Ayman Abdelazem
 Dr. Salah Alnajem, PhD
Dr. Salah Alnajem, PhD
 David Allen
David Allen

 Repustate Team
Repustate Team

