 Home
Home
 Nov 2, 2021
Nov 2, 2021

Arabic Sentiment Analysis Using Repustate IQ
Arabic sentiment analysis is a very valuable business intelligence tool in the Arab world. It is one of the regions with the most social media activity, be it on Twitter, Facebook, or TikTok. Companies can mine valuable customer insights about various facets, right from consumer brands to healthcare, to aspects in politics and environmental research.
In this article, we tell you how brands can leverage Arabic NLP through Repustate IQ to get intelligent market insights. You will also see how Repustate IQ gives the most accurate sentiment insights, thanks to its native Arabic-reading capabilities, setting it apart from all other similar platforms in the market.
How Is Sentiment Mining Of Arabic Text Done Using Repustate IQ?
Repustate IQ reads and understands Standard Arabic and three of its dialects - Gulf Peninsular, Levantine, and Egyptian. It has its own dedicated Arabic lemmatizer, part-of-speech tagger, and sentiment models for each industry. This is what helps it conduct Arabic sentiment analysis through Arabic NLP to understand the semantics in Arabic text and give it a sentiment score. Whether you are looking for TikTok insights or voice of the customer (VoC) analysis, the engine gives you the results you are looking for.
For this example, we will analyze patient voice data that is in Arabic.
- To begin, we log on to Repustate IQ and upload the data comprising comments, complaints, and suggestions that patients have had at a hospital. This data is cleaned and collected in a spreadsheet. It not only has the comments but also the dates on which they were made as well as the source of the comments i.e. call centre logs, email, or sms.
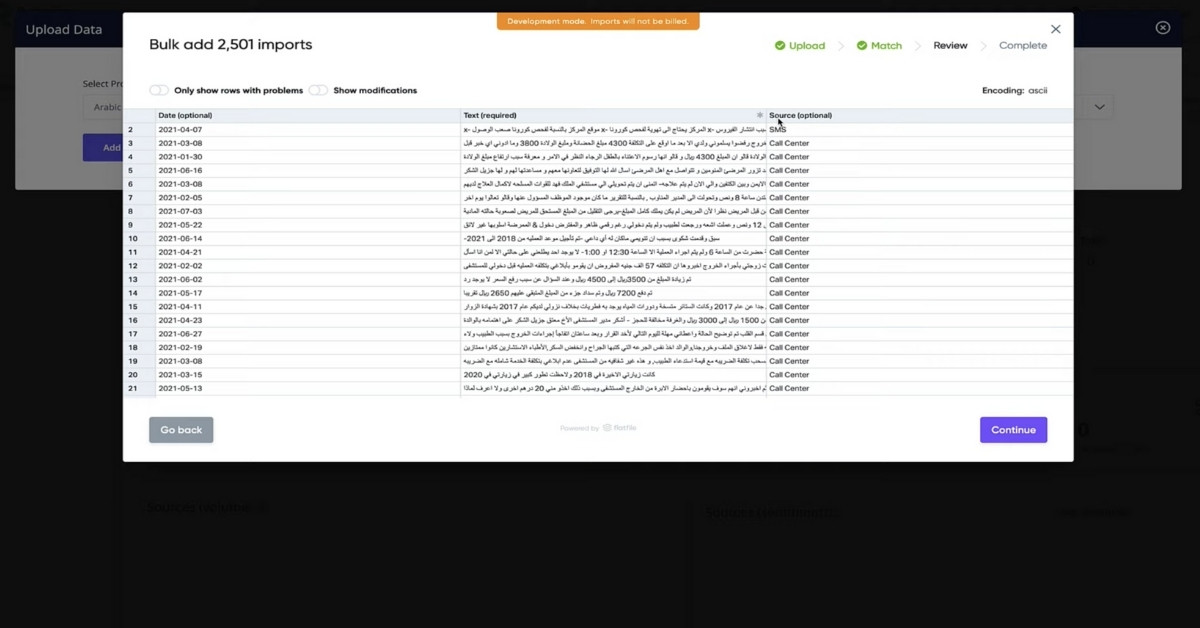
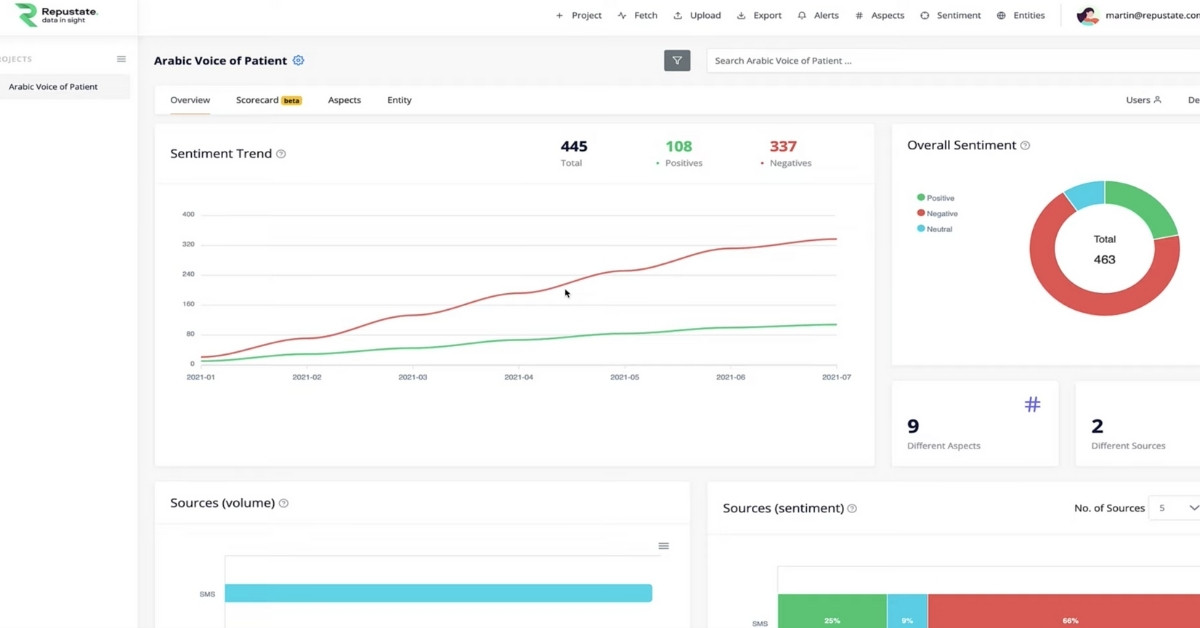
- As soon as the data is uploaded, Repustate IQ’s Arabic NLP immediately and seamlessly processes all the information and gives the results on its visualization dashboard. You can easily see that the platform has identified a growing trend of negative sentiment that customers have about the hospital.
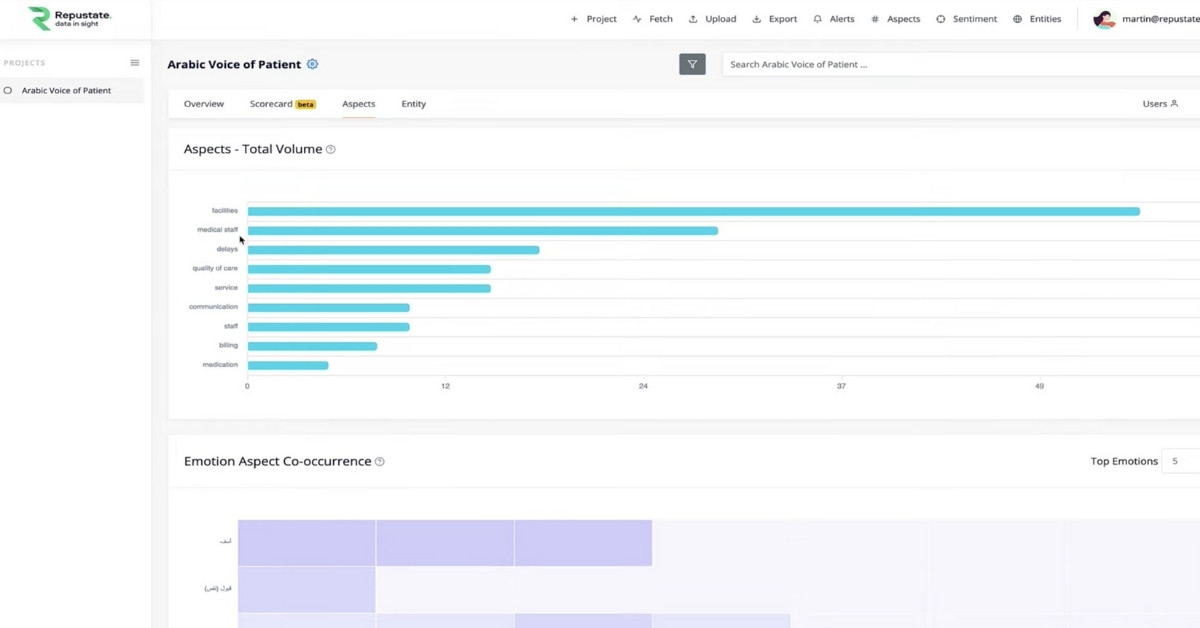
- To dig a little deeper to know the reasons behind this result, we can take a look at the common phrases and words people are using to describe their feelings towards the healthcare provider. We can also see the aspects, and the aspect-emotion co-occurrence to see which emotions are expressed to what extent in relation to which aspect.
In this way, Repustate IQ natively analyzes Arabic data without using any translations so that you can get the most accurate insights from your patient, customer, or employee data.
A very important aspect of Repustate IQ’s Arabic sentiment analysis solution is its encoded Arabic speech tagger, which carries all the nuances, differences, and uniqueness of the Arabic language, making it completely independent of any need for translation. Data scientists at Repustate have developed the named entity recognition (NER) capability and Arabic speech tagger, along with lemmatization and prior polarity, manually - a process that required hours of diligence and efficiency. There are no shortcuts to get the kind of accuracy that Repustate IQ gives.
You have the freedom to choose whatever source of data you need including surveys, reviews, comments, blog, podcasts, social media videos, patient voice data, voice of the employee data, news, online magazine, and many more. This means that your consumer experience insights will be as in-depth and accurate as possible so you can build an effective, data-backed consumer experience strategy.
What are the Major challenges In Arabic Text Mining?
Arabic is a very rich language, which makes Arabic sentiment analysis very complex. Arabic is an official category IV language, which is why it’s not only difficult for non-native learners of the Arabic language but also for machine learning models used for Arabic text mining and sentiment analysis. Below are some of the reasons that make Arabic NLP tough for text analysis.

- Arabic dialects
Arabic is a very complex language, with over 25 dialects, the most commonly spoken being Gulf Peninsula, Egyptian, and Levantine.
- Morphology
The Arabic language comprises derivational morphology or word formations, and inflectional morphology, which is how syntaxes and words are related. There are many integrated dependencies that morphological features have based on word affixes, vowels or word root structures.
- Numerous word formations
Arabic’s high ability for new word formations with rich semantic meanings - all pose quite a challenge for Arabic NLP (natural language processing). The sentiment mining tool needs to be updated on a regular basis, akin to updating a dictionary, to keep adding the new words for their semantic and literal meaning.
- Diversity in semantics
Semantically related words generated from the root of a word ”اقرأ“ (read) can also be diverse, such as ” مكتبة” (library) or “جريدة” (newspaper). This means that the permutations and combinations of Arabic words can be endless.
How Do We Do Arabic Sentiment Analysis Without Translations?
There are 6 essential steps that need to be done to achieve native Arabic sentiment analysis from Arabic data. Through machine learning tasks that include Arabic NLP, all Arabic data is processed for hidden insights and then shown on a sentiment visualization dashboard. Below we explain the steps.
Step 1: Collect Arabic corpus
We collect a vast and varied Arabic corpus or data that is manually tagged. The more diverse the data is, the more efficient and accurate the results from the machine learning model will be.
Step 2: Build an Arabic part-of-speech tagger
We build an Arabic part-of-speech tagger keeping in mind all the morphological derivatives, conjunctions, prepositional phrases, word roots, etc. This speech tagger differentiates Repustate IQ’s Arabic NLP from other platforms in the market.
Step 3: Lemmatization
In this step, lemmatization is done by applying the rules of conjugating nouns and verbs based on tense, root word, gender, and such.
Step 4: Establishing prior polarity
In this step, we determine the polarity of a word. Great could be +1, fair +0.5, and bad as -0.5. This is how the emotions in a comment or text will be analyzed for Arabic sentiment analysis. Ultimately, after calculating all the hundreds of comments, an aggregate score ranging from 0 to 100, 100 being the highest positive score, will be given to the brand the analysis is about.
Step 5: Determine grammatical constructs
Grammatical constructs are determined for Arabic NLP since Arabic has very different rules of negations and the such compared to other languages.
Step 6: Sentiment scores
In this step the machine learning model is fed the sentiment scores for each aspect, feature, or entity. This can be as in-depth as required. The answers will be compared with a validation dataset, and the model retrained if required until it gives the closest, most accurate sentiment scores. All these findings are thus shown in a sentiment analysis dashboard.
If the Arabic data source is video-based, Repusate IQ’s video content analysis will analyze that too for the most accurate scores.
Arabic Text Datasets
As mentioned above, the machine learning model needs to be trained on Arabic NLP using wide and diverse Arabic datasets in order to get the most accurate Arabic sentiment analysis results.
Here are some datasets that can help you.
-
Arabic Learner Corpus (ALC) - This dataset contains written and verbal data developed by more than 900 students in the KSA.
-
Arabic Handwritten Digits - This corpus contains 60,000 training images and 10,000 test images for Arabic NLP. These are handwritten 700 writers.
-
Arabic Poetry Dataset - Here you will find more than 58,000 Arabic poems including the authors.
-
Corpus of Contemporary Arabic (CCA) - This dataset contains 1 million annotated Arabic words.
-
Quranic Arabic Corpus - This dataset comprises Arabic grammar, syntax, and word structure for all the words in the Quran for Arabic NLP
-
Yarmouk Arabic OCR - This dataset has around 9000 images from 4,500+ articles written on Wikipedia written in Arabic. These are great for Arabic NLP.
-
Arabic 100K Reviews - Here will find reviews and comments for 99,999 hotels and product reviews.
See Repustate’s Arabic NLP In Action
Arabic sentiment mining platforms need to analyze Arabic data directly in Arabic in order to get the most accurate insights. Choosing a tool that resorts to translations of the text to English or any other language first, will be a bad decision as this means that none of the insights will be accurate, and more importantly, missing valuable information. Experience Repustate IQ’s Arabic sentiment analysis.
 Jeremy Wemple
Jeremy Wemple
 Dr. Ayman Abdelazem
Dr. Ayman Abdelazem
 Dr. Salah Alnajem, PhD
Dr. Salah Alnajem, PhD
 David Allen
David Allen

 Repustate Team
Repustate Team

