Semantic search software that let's you search across all of your organization's data
Repustate's semantic search allows you to search across any content type, including PDFs, Word documents, emails and even audio and video content.
Book a 15-minute demoWatch this short video to see semantic search in action

Learn how Getting Things Done partnered with Repustate to create a customized semantic search solution and get actionable insights from over 100,000 archived video and audio files.
View all customer success storiesWe were blown away by the fact that Repustate was able to put together a demo using our own YouTube channels on just a couple of days notice.
 David Allen
Author, Speaker and Creator of "Getting Things Done"
David Allen
Author, Speaker and Creator of "Getting Things Done"
What is Enterprise Search?
Enterprise Search helps you search your company's information quickly and accurately. Your company has a lot of data. It's valuable, but when you need to find specific information, it's hard to navigate. With an ever-growing list of data sources and countless file types, finding the data most relevant to you is becoming increasingly difficult. That is where Repustate's Semantic Enterprise Search comes in.
What is Semantic Enterprise Search?
Repustate's AI-driven Semantic Enterprise Search allows you to sift through your enterprise data using natural language to find exactly what you are looking for, 12 times faster, no matter where it lives.
Semantic Search is a more accurate method of searching text data based on the meaning of a query and the intent of the searcher. Semantic Search is more advanced than lexical search which looks for literal keyword matches in a website or document text without any consideration for the meaning of the words associated within the text.
Ultimately, Semantic Search aims to understand the semantic context of a query, rather than just searching for keywords.
USE CASES
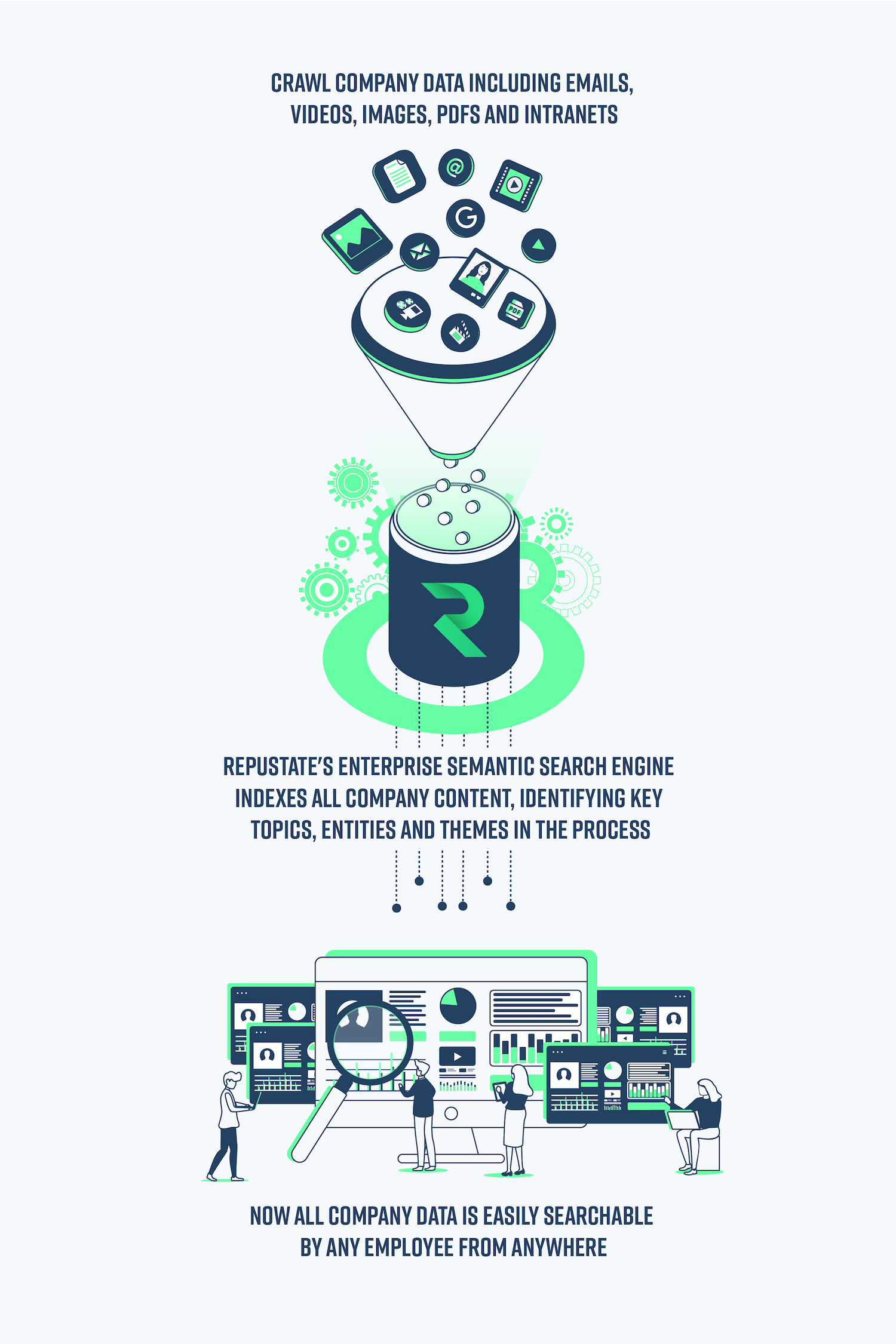
How does semantic search work?
Push your text into your own private Semantic Search index. Any video, audio, images or text, including news, blogs, social media, survey responses, and internal emails, can be indexed by Semantic Search.
Text is indexed instantly by the API and made available for searching – any business, product, brand, person, place or thing is identified, classified, and made searchable.
Semantic Search's intuitive interface makes it easy to search in a more natural way, using entire phrases and natural language rather than just keywords. Search in any language including: Arabic, Chinese, Dutch, French, German, Hebrew, Italian, Japanese, Korean, Polish, Portuguese, Russian, Spanish, Turkish, Thai, Vietnamese and English.
Applications
Semantic Search gives your employees the power to search for desired text content across multiple sources, such as databases and intranets, regardless of document or file type.
Repustate's Semantic Search engine improves workflows and business efficiency by making company knowledge discovery faster, easier, and more accurate.
Industries
The industries that have benefited from Repustate's Semantic Search:
What makes us different?
Fast & Accurate
Repustate's enterprise semantic search delivers the results you want, quickly and effortlessly by leveraging semantic analysis. While traditionals search engines rely on keyword and phrase matching, Repustate's enterprise search engine understands the meaning and context of your text, allowing you to express more powerful and precise queries, finding the exact data you want quicker.
Multilingual
Imagine being able to search your audio, video and text data no matter the language. That dream is now a reality with Repustate's enterprise semantic search. Create one search index for all your multilingual content or separate your content by language, it's up to you. No matter how you choose to organize your data, Repustate's enterprise semantic search engine will find the content you're looking for. And best of all, search your multilingual content in the language of your choosing. A truly multilingual, universal approach to data management - only with Repustate's enterprise semantic search.
Intelligent
An enterprise search tool has to understand the data it's indexing in order to provide accurate search results. That's why Repustate's enterprise semantic search uses machine learning to apply named entity recognition on each document, image or video it analyzes. When you know all of the entities in your documents and how they're related to one another, it's much easier to surface relevant information and discover hidden insights. That's the power of Repustate's enterprise semantic search.
Easy Deployment
Repustate's enterprise semantic search is available via public cloud API or as an on-premise install. Our Enterprise Semantic Search can be quickly customized and implemented for you and your company's needs, integrating seamlessly into your existing tech stack with all major operating systems and the most popular databases supported.
Book a personalized 15-minute demo to learn more about Repustate's semantic search
Book a 15-minute demo todayCustomizable
Semantic Search, while having many applications, cannot be applied in a “one-size-fits-all”. Language is nuanced – from industry to industry, from data source to data source. Repustate's approach to Enterprise Semantic Search is to cater to the needs of individual customers, allowing them to tweak and customize our Semantic Search engine to best fit their goals.
Private & Secure
No data or customer information sent to Repustate is ever stored on Repustate servers or shared with any other 3rd party. Repustate employees are forbidden from looking at any transient data passed to the Repustate API unless explicitly asked to do so by a customer.
Scalable
With the ever-increasing amount of data being generated, the ability to quickly analyze and extract useful information from data, regardless of source, is paramount to any good software product. Repustate's API regularly handles billions of API calls per day, allowing developers to process API requests in parallel and in bulk to improve throughput.
Support
Your dedicated engineer is always available for support calls. That means no time waiting on hold – no filing tickets and waiting for a response. Our client success team will work with you to plan, measure and report on partnership metrics that ensure you exceed your goals on an on-going basis. Repustate's success objective is that every client optimizes the strategic value of their text data insights and their tangible application to real-time business challenges.